コンテンツ
- 定義-Apache Kuduはどういう意味ですか?
- Microsoft AzureとMicrosoft Cloudの紹介|このガイドを通して、クラウドコンピューティングとは何か、Microsoft Azureを使用してクラウドからビジネスを移行および実行する方法を学習します。
- TechopediaはApache Kuduを説明します
定義-Apache Kuduはどういう意味ですか?
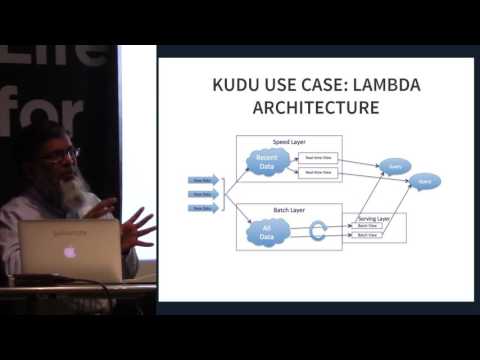
Apache Kuduは、オープンソースのApache Hadoopエコシステムのメンバーです。これは、低遅延のランダムアクセスと効率的な分析アクセスパターンをサポートする構造化データ向けのオープンソースストレージエンジンです。広く使用されているHadoop分散ファイルシステム(HDFS)とHBase NoSQLデータベースのギャップを埋めるために設計および実装されました。これらのシステムは依然として有利であることが証明されていますが、Apache Kuduはアーキテクチャを劇的に簡素化できるため、多くの一般的なワークロードに対応できます。
Microsoft AzureとMicrosoft Cloudの紹介|このガイドを通して、クラウドコンピューティングとは何か、Microsoft Azureを使用してクラウドからビジネスを移行および実行する方法を学習します。
TechopediaはApache Kuduを説明します
Apache Kuduは、主にClouderaのプロジェクトとして開発されました。これまでの貢献のほとんどは、Clouderaで採用されている開発者によるものです。リリース中、Clouderaのリポジトリにはコンビニエンスバイナリのみが含まれていましたが、インキュベーターに参加すると、Apache Software Foundation(ASF)ソースリリースプロセスが採用されました。高速データの高速分析が必要なユースケース向けに特別に設計されています。次世代のハードウェアとメモリ内処理を活用するように設計されました。 Apache ImpalaおよびApache Sparkのクエリレイテンシを大幅に短縮します。カラムナーストレージエンジンまたは水平パーティショニングを介してデータを配信し、Raftコンセンサスを使用して各パーティションを複製することで、平均復旧時間とテールレイテンシを低減します。
Kuduは、Apache Hadoopエコシステムの短所内で設計された製品ですが、ASF内外のデータ分析プロジェクトとの統合もサポートしています。
Apache Kuduは、単一のストレージレイヤー全体でリアルタイムの分析ワークロードを処理できるため、効率的であることが証明されています。そのため、アーキテクトは、エキゾチックな回避策なしで幅広い用途に柔軟に対応できます。